



容器与进程
何为容器:
假如要写一个计算加法的小程序,这个程序需要的输入来自于一个文件,计算完成后的结果则输出到另一个文件中。
由于计算机只认0和1,无论用哪种语言编写这段代码,最后都要通过某种方式编译成二进制文件,才能在计算机操作系统中运行起来。
而为了能够让这些代码正常运行,往往还要给它提供数据,比如这个加法程序所需的输入文件。这些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个"程序",也叫代码的可执行镜像(executable image)
然后,就可以在计算机上运行这个"程序"了。
首先,操作系统从"程序"中发现输入数据保存在一个文件中,所以这些数据会被加载到内存中待命。同时,操作系统又读取到了计算加法的指令,这时,他就需要指示CPU完成加法操作。而CPU与内存协作进行加法计算,又会使用寄存器存放数值、内存堆栈保存执行的命令和变量。同时,计算机里面还有被打开的文件,以及各种各样的I/O设备在不断地调用中修改自己的状态
就这样,一旦"程序"被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运行起来后的计算机执行环境的总和,就是:进程。
所以,对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,他就变成了计算机里的数据和状态的总和,这就是它的动态表现
容器与进程:
而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个"边界"。
认识Namespace
Linux 容器中用来实现"隔离"的技术手段:Namespace。Namespace技术实际上修改了应用进程看待整个计算机"视图",即它的"视线"操作系统做了限制,只能"看到"某些指定的内容。但对于宿主机来说,这些被"隔离"了的进程跟其他进程并没有太大区别。
假设已经有一个 Linux 操作系统的Docker项目在运行,环境为:Centos 7和Docker CE 18.05
1.创建一个容器
[root@docker ~]# docker run -it daocloud.io/library/centos:7 /bin/bash
[root@e6f92976da77 /]#
这条指令翻译成人类的语言就是:请帮助我启动一个容器,在容器里执行/bin/bash,并且给我分配一个命令行终端跟这个容器交互。
这样,这台coentos机器就编程了一个宿主机,而一个运行着/bin/bash的容器,就跑在了这个宿主机里面。
2.在容器里执行ps指令,会发现一些有趣的事情:/bin/bash,就是这个容器内部的第1号进程(PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的/bin/bash,以及我们刚刚执行的ps,已经被Docker隔离在了这一个跟宿主机完全不同的世界当中。
/# ps
PID USER TIME COMMAND
1 root 0:00 /bin/bash
10 root 0:00 ps
本来,每当在宿主机上运行一个/bin/bash程序,操作系统都会给它分配一个进程编号,比如PID=100。这个编号是进程的唯一标识,就像员工的工牌一样,所以PID=100,可以粗略地理解为这个/bin/bash是我们公司里的第100号员工,而第1号员工自然是比尔·盖茨这样统领全局的人物。
而现在,要通过Docker把/bin/bash运行在一个容器当中,这时,Docker就会在这个第100号员工入职时给它施一个"障眼法"让他永远看不到前面的其他99个员工,更看不到1号员工,这样,他就会错误地认为自己就是公司里的第1号员工。
这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进程只能看到重新计算过的进程编号,比如 PID=1。可实际上,他们在宿主机的操作系统里,还是原来的第100号进程。
这种技术,就是Linux里面的Namespace机制。
深入理解Namespace机制
Namespace的使用方式:
其实只是Linux创建新进程的一个可选参数。
在Linux系统中创建线程的系统调用是clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
这个系统调用就会为我们创建一个新的进程,并且返回它的进程号pid。
当用clone()系统调用创建一个心得进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, statk_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会"看到"一个全新的进程空间,在这空间里,它的PID是1,之所以说"看到",是因为这只是一个"障眼法",在宿主机真实的进程空间里,这个进程的PID还是真实的数值,比如 100。
多次执行上面的clone()调用,就会创建多个PID Namespae,而每个Namespace里的应用进程,都会认为自己是当前容器里的第1号进程,它们即看不到宿主机里真正的进程空间,也看不到其他PID Namespace里的具体情况。
而除了刚用到的PID Namespace,Linux操作系统还提供了Mount、UTS、IPC、Network和User这些Namespace,用来对各种不同的进程上下文进行"障眼法"操作。
比如,Mount Namespace,用来让被隔离进程只看到当前Namespace里的挂载点信息;Network Namespace,用来让被隔离进程看到当前Namespace里的网络设备和配置。
这,就是Linux容器最基本的实现原理了。
所以,Docker容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组Namespace参数。这样,容器就只能"看"到当前Namespace所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就看不到了。
所以说,容器,其实是一种特殊的进程而已。
深入理解Cgroup机制
Linux中,Cgroups给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的/sys/fs/cgroup路径下。
用mount指令把它们展示出来:
[root@docker ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
··· ···
输出结果,是一系列文件系统目录。在/sys/fs/cgroup下面有很多诸如cpuset、cpu、memory这样的子目录。也叫子系统,这些都是这台机器当前可以被Cgroups进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。
比如,对CPU子系统来说,可以看到如下几个配置文件:
[root@docker ~]# cd /sys/fs/cgroup/
[root@docker cgroup]# ls
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids systemd
比如:cfs_period和cfs_quots 这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period的一段时间内,只能被分配到总量为 cfs_quota的CPU时间。
实验验证:
1、需要在对应的子系统下面创建一个目录,这个目录称为一个"控制组",操作系统会在你新创建的目录下,自动生成该子系统对应的资源限制文件。
[root@docker ~]# cd /sys/fs/cgroup/cpu
[root@docker cpu]# mkdir container
[root@docker cpu]# ls
cgroup.clone_children cgroup.procs container cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares docker release_agent tasks
cgroup.event_control cgroup.sane_behavior cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat notify_on_release system.slice user.slice
2、在后台执行一条脚本
[root@docker cpu]# while : ; do : ; done &
[1] 73898
它执行了一个死循环,可以把计算机的CPU吃到100%,根据它的输出,可以看到这个脚本在后台运行的进程号(PID)是73898
3、用top指令确认一下CPU有没有被打满,用1分看查看cpu
[root@docker cpu]# top
%Cpu1 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
在输出里可以看到,CPU的是用率已经100%了。
此时,通过查看container目录下的文件,看到container控制组里的CPU quota还没有任何限制(即:-1),CPU period则是默认的100ms(100000 us);
[root@docker cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
[root@docker cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
4、通过修改这些文件的内容来设置限制
比如,向container组里的cfs_quota文件写入20ms(20000 us);
[root@docker cpu]# echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
意味着每100ms的时间里,被该控制组限制的进程只能使用20ms的CPU时间,也就是说这个进程只能使用到20%的cpu带宽。
5、把被限制的进程的PID写入container组里的tasks文件,上面的设置就会对该进程生效:
[root@docker cpu]# echo 73898 > /sys/fs/cgroup/cpu/container/tasks
6、再次用top查看,验证效果:
[root@docker cpu]# top
%Cpu1 : 7.6 us, 0.0 sy, 0.0 ni, 92.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
可以看到,计算机的CPU使用率降到了20%。
除了CPU子系统外,Cgroups的每一项子系统都有其独有的资源限制能力
blkio:
为···块···设···备···设···定···I/O 限···制,一般用于磁盘等设备;
cpuset:
为进程分配单独的CPU核和对应的内存节点;
memory:
为进程设定内存使用的限制。
Linux Cgroups的设计,简单粗暴地理解,就是一个子系统目录加上一组资源限制文件的组合。而对于Docker等Linux容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的PID填写到对应控制组的tasks文件中就可以了。
至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
# docker run -it --cpu-period=100000 --cpu-quota=20000 daocloud.io/centos /bin/bash
在启动这个容器后,通过查看 Cgroups 文件系统下,CPU子系统中,"docker"这个控制组里的资源限制文件的内容来确认:
# cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
# cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
在centos7里面是下面这个目录:不是上面的docker目录
# cat /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-92f7652e9c0c34e0f4j4bkj5bk3bk5kj849gb445b6i09845m13209.scope/cpu.cfs_quota_us
20000
这就意味着这个Docker容器,只能使用到20%的CPU带宽。
由于一个容器的本质就是一个进程,用户的应用进程实际上就是容器里 PID=1 的进程,也是其他后续创建的所有进程的父进程。这就意味着,在一个容器中,你没办法同时运行两个不同的应用,除非你能事先找到一个公共的 PID=1 的程序来充当两个不同应用的父进程,这也是为什么很多人都会用 system 或者 supervisord 这样的软件来代替应用本事作为容器的启动进程。
这是因为容器本事的设计,就是希望容器和应用能够同生命周期,这个概念对后续的容器编排非常重要。否则,一旦出现类似于"容器是正常运行的,但是里面的应用早已经挂了"的情况,编排系统处理起来就非常麻烦了。
理解容器文件系统
Overlayfs
Overlayfs是一种类似aufs的一种堆叠文件系统,于2014年正式合入Linux-3.18主线内核,目前其功能已经基本稳定(虽然还存在一些特性尚未实现) 且被逐渐推广,特别在容器技术中更是势头难当。
它依赖并建立在其他的文件系统之上(例如ext4fs和xfs等等),并不直接参与磁盘空间结构的划分,仅仅将原来底层文件系统中不同的目录进行"合并",然后向用户呈现,因此对于用户来说,他所见到的overlay文件系统根目录下的内容就来自挂载时所指定的不同目录的"合集"。
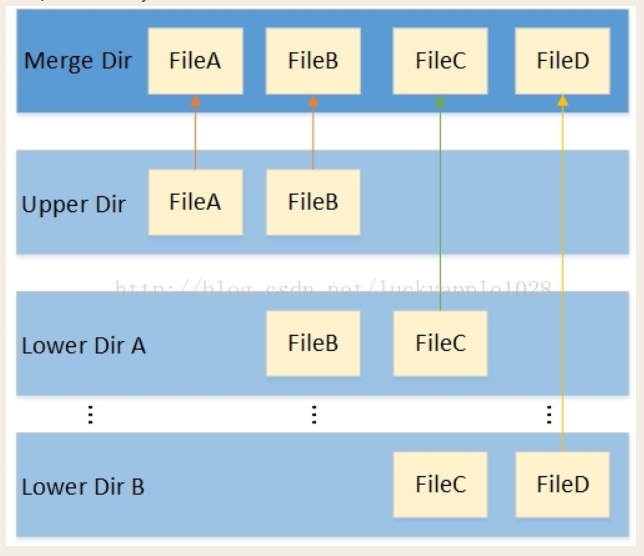
overlayfs最基本的特性,简单的总结为以下3点:
(1)上下层同名目录合并;
(2)上下层同名文件覆盖;
(3)lower dir文件写时拷贝;
这三点对用户都是不感知的。
lower dirA / lower dirB 目录和upper dir目录
- 他们都是来自底层文件系统的不同目录,用户可以自行指定,内部包含了用户想要合并的文件和目录,merge dir目录为挂载点。
- 当文件系统挂载后,在merge目录下将会同时看到来自各lower和upper目录下的内容,并且用户也无法(无需)感知这些文件分别那些来自lower dir,哪些来自upper dir,用户看见的只是一个普通的文件系统根目录而已(lower dir可以有多个也可以只有一个)。
upper dir和各lower dir这几个不同的目录并不完全等价,存在层次关系。
- 当upper dir和lower dir两个目录存在同名文件时,lower dir的文件将会被隐藏,用户只能看见来自upper dir的文件
- lower dir也存在相同的层次关系,较上层屏蔽较下层的同名文件。
- 如果存在同名的目录,那就继续合并(lower dir和upper dir合并到挂载点目录其实就是合并一个典型的例子)。
读写数据:
- 各层目录中的upper dir是可读写的目录,当用户通过merge dir向其中一个来自upper dir的文件写入数据时,那数据将直接写入upper dir下原来的文件中,删除文件也是用同理;
- 而各lower dir则是只读的,在overlayfs挂载后无论如何操作merge目录中对应来自lower dir的文件或目录,lower dir中的内容均不会发生任何的改变。
- 当用户想要往来自lower层的文件添加或修改内容时,overlayfs首先会拷贝一份lower dir中的文件副本到upper dir中,后续的写入和修改操作将会在upper dir下的copy-up的副本文件中进行,lower dir原文件被隐藏。
overlayfs特性带来的好处和应用场景
实际的使用中,会存在以下的多用户复用共享文件和目录的场景
见图
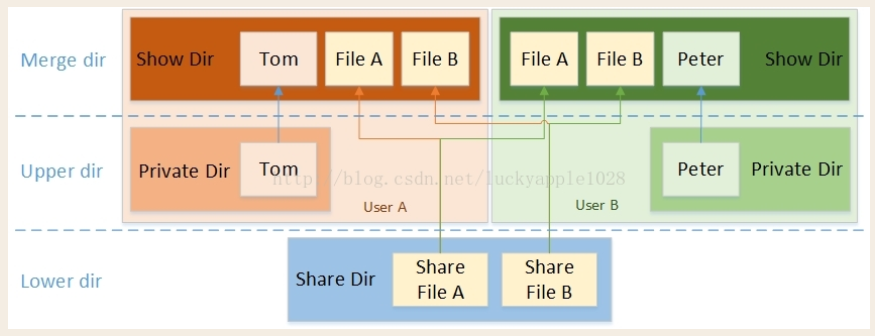
复用共享目录文件
在同一个设备上,用户A和用户B有一些共同使用的共享文件(例如运行程序所依赖的动态链接库等),一般是只读的;同时也有自己的私有文件(例如系统配置文件等),往往是需要能够写入修改的;最后即使用户A修改了被共享的文件也不会影响到用户B。
对于以上的需求场景,我们并不希望每个用户都有一份完全一样的文件副本,因为这样不仅带来空间的浪费也会影响性能,因此overlayfs是一个较为完美的解决方案。我们将这些共享的文件和目录所在的目录设定为lower dir (1~n),将用户私有的文件和目录所在的目录设定为upper dir,然后挂载到用户指定的挂载点,这样即能够保证前面列出的3点需求,同时也能够保证用户A和B独有的目录树结构。最后最为关键的是用户A和用户B在各自挂载目录下看见的共享文件其实是同一个文件,这样磁盘空间的节省自是不必说了,还有就是共享同一份cache而减少内存的使用和提高访问性能,因为只要cache不被回收,只需某个用户首次访问时创建cache,后续其他所有用户都可以通过访问cache来提高IO性能。
上面说的这种使用场景在容器技术中应用最为广泛
Overlay和Overlay2
以Docker容器为例来介绍overlay的两种应用方式:Overlay和Overlay2
- Docker容器将镜像层(image layer)作为lower dir
- 将容器层(container layer)作为upper dir
- 最后挂载到容器merge挂载点,即容器的根目录下。
遗憾的是,早期内核中的overlayfs并不支持多lower layer,在Linux-4.0以后的内核版本中才陆续支持完善。而容器中可能存在多层镜像,所以出现了两种overlayfs的挂载方式,早期的overlay不使用多lower layer的方式挂载而overlay2则使用该方式挂载。
- Overlay Driver
Overlay挂载方式如下
—该图引用自Miklos Szeredi的《overlayfs and containers》2017 Linux内核大会演讲材料
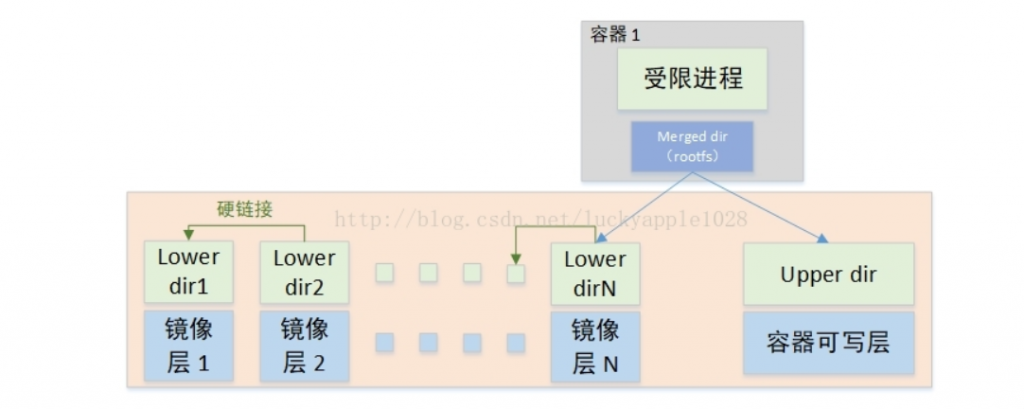
Overlay2 Driver
Overlay2的挂载方式比Overlay的要简单许多,它基于内核overlayfs的Multiple lower layers特性实现,不在需要硬链接,直接将镜像层的各个目录设置为overlayfs的各个lower layer即可(Overlayfs最多支持500层lower dir),对比Overlay Driver将减少inode的使用。
分别查看镜像的详细信息和运行成容器之后的容器详细信息
lower1:lower2:lower3:
表示不同的lower层目录,不同的目录使用":"分隔,层次关系依次为lower1 > lower2 > lower3
注:多lower层功能支持在Linux-4.0合入,Linux-3.18版本只能指定一个lower dir
评论区