



Kubernetes容器编排技术
容器编排之战
Kubernetes是谷歌严格保密十几年的秘密武器-Borg的一个开源版本,是Docker分布式系统解决方案。
2014年由Google公司启动
Borg
Borg是谷歌内部使用的大规模集群管理系统,基于容器技术,目的是实现资源管理的自动化,以及跨多个数据中心的资源利用率的最大化
容器编排引擎三足鼎立:
- Mesos
- Docker Swarm+compose
- Kubernetes
早在2015年5月,Kubernetes在Google上的搜索热度就已经超过了Mesos和Docker Swarm,从那儿之后更是一路飙升,将对手甩开了十几条街,容器编排引擎的三足鼎立时代结束。
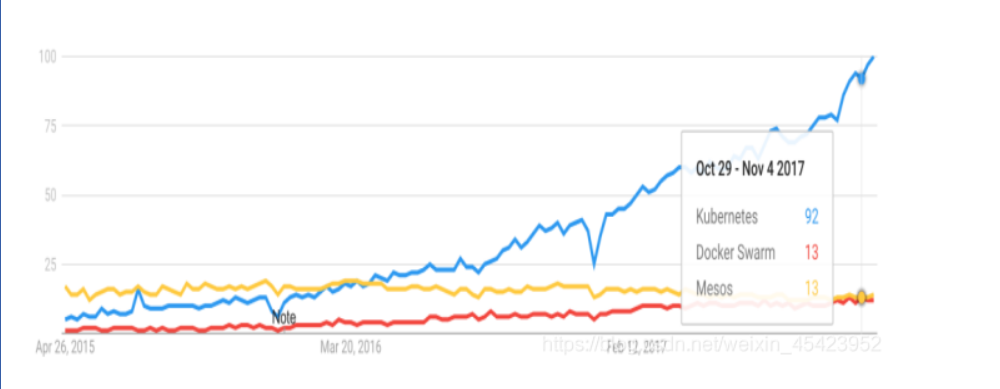
目前,AWS、Azure、Google、阿里云、腾讯云等主流公有云提供的是基于kubernetes的容器服务:Rancher、CoreOS、IBM、Mirantis、Oracle、Red Hat、VMware等无数厂商也在大力研发和推广基于kubernetes的容器Caas或Paas产品,可以说,Kubernetes是当前容器行业最炙手可热的明星。
Google 的数据中心里运行着超过 20 亿个容器,而且 Google 十年前就开始使用容器技术。
最初,Google 开发了一个叫 Borg 的系统(现在命名为 Omega)来调度如此庞大数量的容器和工作负载。在积累了这么多年的经验后,Google 决定重写这个容器管理系统,并将其贡献到开源社区,让全世界都能受益。这个项目就是 Kubernetes。简单的讲,Kubernetes 是 Google Omega 的开源版本。
跟很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes 项目的理论基础则要比工程实践走得靠前得多,这当然要归功于 Google 公司在 2015 年 4 月发布的 Borg 论文了。
Borg 系统,一直以来都被誉为 Google 公司内部最强大的"秘密武器"。虽然略显夸张,但这个说法倒不算是吹牛。
因为,相比于 Spanner、BigTable 等相对上层的项目,Borg 要承担的责任,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层。
由于这样的定位,Borg 可以说是 Google 最不可能开源的一个项目。而幸运地是,得益于 Docker 项目和容器技术的风靡,它却终于得以以另一种方式与开源社区见面,这个方式就是 Kubernetes 项目。
所以,相比于"小打小闹"的 Docker 公司、"旧瓶装新酒"的 Mesos 社区,Kubernetes 项目从一开始就比较幸运地站上了一个他人难以企及的高度:在它的成长阶段,这个项目每一个核心特性的提出,几乎都脱胎于 Borg/Omega 系统的设计与经验。更重要的是,这些特性在开源社区落地的过程中,又在整个社区的合力之下得到了极大的改进,修复了很多当年遗留在 Borg 体系中的缺陷和问题。
所以,尽管在发布之初被批评是"曲高和寡",但是在逐渐觉察到 Docker 技术栈的"稚嫩"和 Mesos 社区的"老迈"之后,这个社区很快就明白了:k8s 项目在 Borg 体系的指导下,体现出了一种独有的"先进性"与"完备性",而这些特质才是一个基础设施领域开源项目赖以生存的核心价值。
为什么是编排
一个正在运行的Linux容器,可以分成两部分看待:
1.容器的静态视图
-一组联合挂载在/var/lib/docker/aufs/mnt 上的rootfs,这一部分称为"容器镜像"(Container Image)
2.容器的动态视图
-一个由Namespace + Cgroups构成的隔离环境,这一部分称为"容器运行时"(Container Runtime)
作为一名开发者,其实并不关心容器运行时的差异。在整个"开发 - 测试 - 发布"的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
这正是容器技术圈在 Docker 项目成功后不久,就迅速走向了"容器编排"这个"上层建筑"的主要原因:作为一家云服务商或者基础设施提供商,我只要能够将用户提交的 Docker 镜像以容器的方式运行起来,就能成为这个非常热闹的容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在我的这个节点上。
更重要的是,只要从这个承载点向 Docker 镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如 CI/CD、监控、安全、网络、存储等等,都有可以发挥和盈利的余地。这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和潜在用户(即,开发者)直接关联起来。
从一个开发者和单一的容器镜像,到无数开发者和庞大的容器集群,容器技术实现了从"容器"到"容器云"的飞跃,标志着它真正得到了市场和生态的认可。
这样,容器就从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角;而能够定义容器组织和管理规范的"容器编排"技术,则当仁不让地坐上了容器技术领域的"头把交椅"。
最具代表性的容器编排工具:
1.Docker 公司的 Compose + Swarm组合
2.Google 与 RedHat 公司共同主导的Kubernetes项目
理解容器编排
Docker平台以及周边生态系统包含很多工具来管理容器的生命周期。例如,Docker Command Line Interface(CLI)满足在单个主机上管理容器的需求,但是面对部署在多个主机上的容器时就无所适从了。为了超越单个容器管理,我们必须转向编排工具。容器编排工具将生命周期管理能力扩展到部署在大量机器集群上部署的复杂的、多容器工作负载。
容器编排工具为开发人员和基础设施团队提供了一个抽象层来处理大规模的容器化部署。容器编排工具提供的特征在众多提供者之间有所不同,然而常见的公共特征包含准备、发现、资源管理、监视和部署。
由于微服务将应用程序分解为不同的微应用程序,许多开发人员会请求更多的服务器节点进行部署。为了正确地管理微服务,开发者倾向于在每个VM中部署一个微服务,这进一步降低了资源利用率。在许多情况下,这会导致CPU和内存的过度分配。
在许多部署中,微服务的高可用性需求迫使工程师添加越来越多的服务实例来进行冗余。实际上,尽管它提供了所需的高可用性,但这将导致出现一些未充分利用的服务器实例。一般而言,与单一应用程序部署相比,微服务部署需要更多的基础设施。由于基础设施成本的增加,许多组织未能看到微服务的价值。
为了解决上面提到的问题,我们需要一个工具能做到以下几点:
- 活动自动化。例如有效地向基础设施分配容器,这一行为对开发人员和管理员都是透明的。
- 为开发人员提供一个抽象层,以便他们可以在不知道使用哪个机器托管他们的应用程序的情况下,将应用程序部署到数据中心。
- 对部署设置规则或约束。
- 提供更高的敏捷性,为开发人员和管理员提供最小的管理开销和最少的人为交互。
- 通过最大限度地利用可用资源,有效地构建、部署和管理应用程序。
典型的容器编排工具有助于虚拟化一组机器并将它们作为单个集群管理。容器编排工具也有助于将机器上的工作负载或容器移动到消费者透明的位置。很多工具目前既支持基于DOCKER的容器,也支持非容器化二进制文件部署,例如独立的Spring Boot应用程序。这些容器编排工具的基本功能是从应用程序中抽象出实际的服务器实例。
容器编排工具的一些关键能力概括如下:
- 集群管理:将虚拟机和物理机器的集群管理为一台大型机器。这些机器在资源能力方面可能有些差异,但大体上都是以Linux作为操作系统的机器。这些虚拟集群可以建立在云上、本地或两者的混合。
- 部署:能处理有大量机器的应用程序和容器的自动部署。支持多个版本的应用程序容器,并且还支持跨越大量集群机器的滚动升级。这些工具还能够处理故障回滚。
- 可伸缩性:支持应用实例的自动和手动伸缩,以性能优化为主要目标。
- 基础结构抽象化:开发人员不必担心机器、容量等问题。完全是容器编排工具来决定如何调度和运行应用程序。这些工具也抽象化机器的细节、能力、使用和位置。对于应用程序所有者来说,它们相当于一个容量几乎无限的大型机器。
- 资源优化:这些工具以有效的方式在一组可用机器上分配容器工作负载,从而降低成本,通过从简单的到复杂的算法可有效地提高利用率。
- 资源分配:基于应用程序开发人员设置的资源可用性和约束来分配服务器。资源分配将基于约束、规则、端口要求、应用依赖性、健康等等。
- 服务可用性:确保服务在集群中正常运行。在机器故障的情况下,容器编排会自动通过在集群中的其他机器上重新启动这些服务来处理故障。
- 敏捷性:敏捷性工具能够快速分配工作负载到可用资源,或者在资源需求发生变化时跨机器移动工作量。此外,可以根据业务临界性、业务优先级等来设置约束重新调整资源。
- 隔离:一些工具提供了资源隔离。因此,即使应用程序不是容器化的,也可以实现资源隔离。
Kubernetes介绍
首先,他是一个全新的基于容器技术的分布式架构领先方案。Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg)。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。
Kubernetes是一个完备的分布式系统支撑平台,具有完备的集群管理能力,多扩多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。同时Kubernetes提供完善的管理工具,涵盖了包括开发、部署测试、运维监控在内的各个环节。
Kubernetes中,Service是分布式集群架构的核心,一个service对象拥有如下关键特征:
拥有一个唯一指定的名字
拥有一个虚拟IP(Cluster IP、Service IP、或VIP)和端口号
能够体统某种远程服务能力
被映射到了提供这种服务能力的一组容器应用上
Service的服务进程目前都是基于Socket通信方式对外提供服务,比如Redis、Memcache、MySQL、Web Server,或者是实现了某个具体业务的一个特定的TCP Server进程,虽然一个Service通常由多个相关的服务进程来提供服务,每个服务进程都有一个独立的Endpoint(IP+Port)访问点,但Kubernetes能够让我们通过服务连接到指定的Service上。有了Kubernetes内奸的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响我们队服务的正常调用,更重要的是这个Service本身一旦创建就不会发生变化,意味着在Kubernetes集群中,我们不用为了服务的IP地址的变化问题而头疼了。
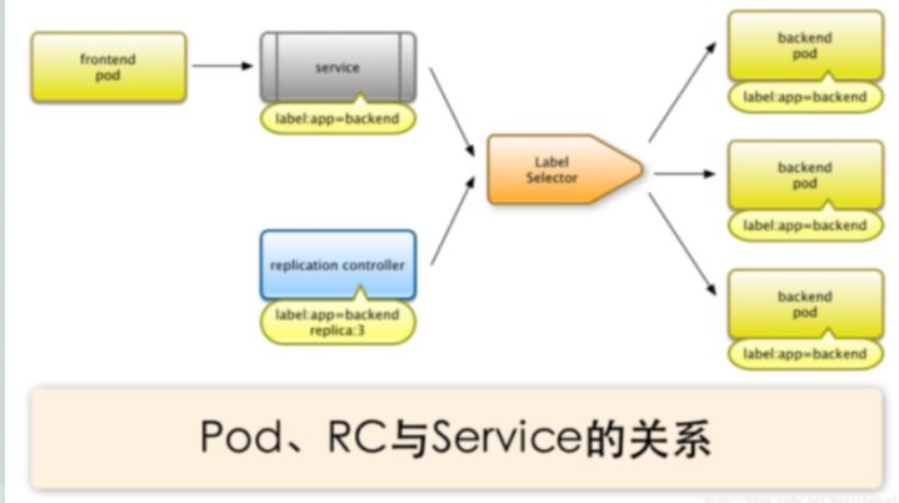
容器提供了强大的隔离功能,所有有必要把为Service提供服务的这组进程放入容器中进行隔离。为此,Kubernetes设计了Pod对象,将每个服务进程包装到相对应的Pod中,使其成为Pod中运行的一个容器。为了建立Service与Pod间的关联管理,Kubernetes给每个Pod贴上一个标签Label,比如运行MySQL的Pod贴上name=mysql标签,给运行PHP的Pod贴上name=php标签,然后给相应的Service定义标签选择器Label Selector,这样就能巧妙的解决了Service于Pod的关联问题。
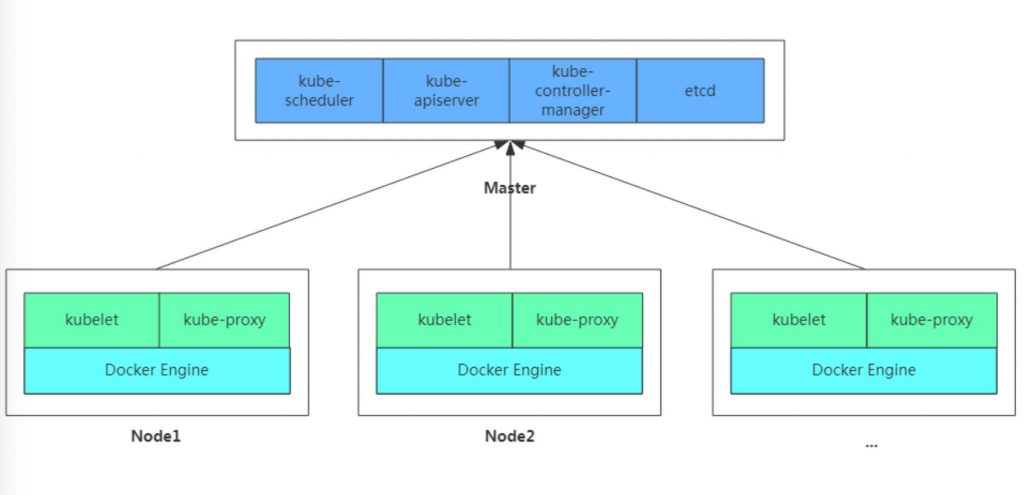
在集群管理方面,Kubernetes将集群中的机器划分为一个Master节点和一群工作节点Node,其中,在Master节点运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理能力,并且都是全自动完成的。Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁以及实现软件模式的负载均衡器。
在Kubernetes集群中,它解决了传统IT系统中服务扩容和升级的两大难题。你只需为需要扩容的Service关联的Pod创建一个Replication Controller简称(RC),则该Service的扩容及后续的升级等问题将迎刃而解。在一个RC定义文件中包括以下3个关键信息。
- 目标Pod的定义
- 目标Pod需要运行的副本数量(Replicas)
- 要监控的目标Pod标签(Label)
在创建好RC后,Kubernetes会通过RC中定义的的Label筛选出对应Pod实例并实时监控其状态和数量,如果实例数量少于定义的副本数量,则会根据RC中定义的Pod模板来创建一个新的Pod,然后将新Pod调度到合适的Node上启动运行,知道Pod实例的数量达到预定目标,这个过程完全是自动化。
Kubernetes优势:
-容器编排
-轻量级
-开源
-弹性伸缩
-负载均衡
Kubernetes核心概念详解
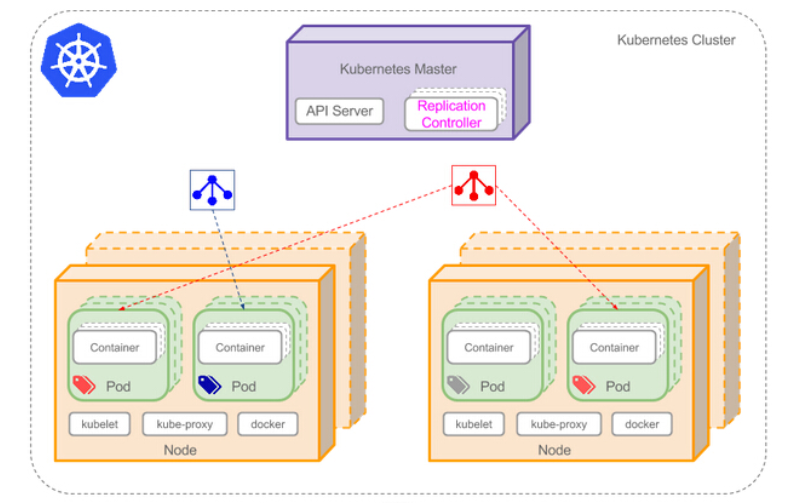
上图可以看到如下组件,使用特别的图标表示Service和Label:
- Pod
- Container(容器)
- Label(标签)
- Replication Controller(复制控制器)
- Service(服务)
- Node(节点)
- Kubernetes Master(Kubernetes主节点)
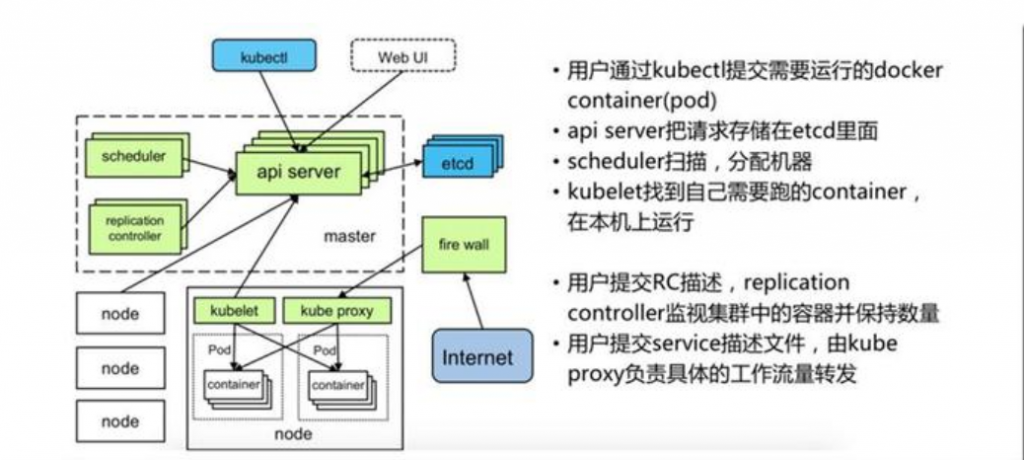
Master
Master主要负责资源调度,控制副本,和提供统一访问集群的入口。
Node
Node由Master管理,并汇报容器状态给Master,同时根据Master要求管理容器生命周期
Node IP
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的ip地址,是真实存在的物理网络,所有属于这个网络的服务器之间都能通过或者网络直接通信;
Pod
Pod直译是豆荚,可以把容器想象成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个pod)。在k8s中我们不会直接操作容器,而是把容器包装成Pod再进行管理
运行于Node节点上,若干相关容器的组合。Pod内包含的容器运行在同一宿主机上,使用相同的网络命令空间,IP地址和端口,能够通过localhost进行通信。Pod是k8s进行创建、调度和管理的最小单位,它提供了比容器更高层次额抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。
Pod就是k8s世界里的"应用";而一个应用,可以由多个容器组成。

pause容器
每个Pod中都有一个pause容器,pause容器做为Pod的网络接入点,Pod中其他的容器会使用容器映射模式启动并接入到这个pause容器。
属于同一个Pod的所有容器共享网络的namespace。
一个Pod里的容器与另外主机上的Pod容器能够直接通信;
如果Pod所在的Node宕机,会将这个Node上的所有Pod重新调度到其他节点上;
Pod Volume:
Docker Volume对应Kubernetes中的Pod Volume;
资源限制:
每个Pod可以设置限制的计算机资源由CPU和Memory;
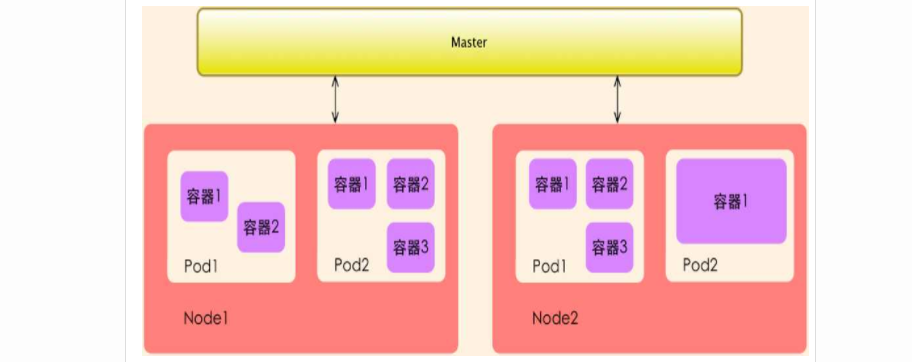
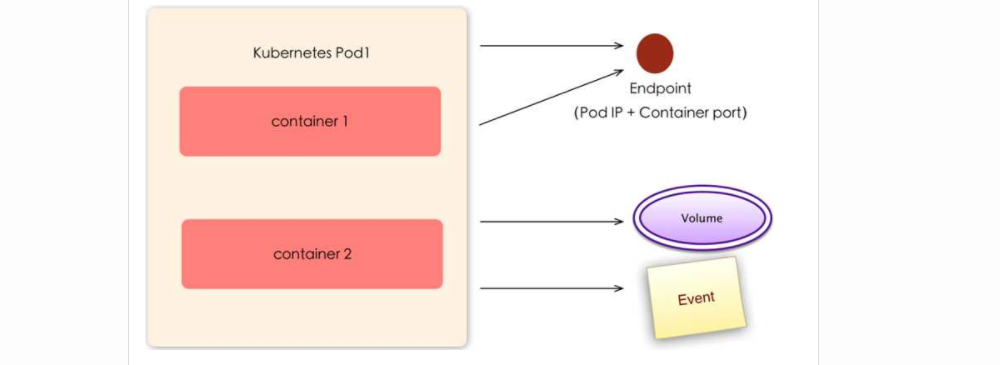
Pod及周边对象
Event
是一个事件记录,记录了事件最早生产的时间、最后重复时间、重复次数、发起者、类型,以及导致事件的原因等信息。Event通常关联到具体资源对象上,是排查故障的重要参考信息
Pod IP
Pod的IP地址,是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,位于不同Node上的Pod能够彼此通信,需要通过Pod IP所在的虚拟二层网络进行通信,而真实的TCP流量则是通过Node IP所在的物理网卡流出的
Namespace
命名空间将资源对象逻辑上分配到不同Namespace,可以是不同的项目、用户等区分管理,并设定控制策略,从而实现多租户。命名空间也称为虚拟集群。
Replica Set
确保任何给定时间指定的Pod副本数量,并提供声明式更新等功能。
Deployment
Deployment是一个更高层次的API对象,它管理ReplicaSets和Pod,并提供声明式更新等功能。
官方建议使用Deployment管理ReplicaSets,而不是直接使用ReplicaSets,这就意味着可能永远不需要直接操作ReplicaSet对象,因此Deployment将会是使用最频繁的资源对象。
RC-Replication Controller
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
部署和升级Pod,声明某种Pod的副本数量在任意时刻都符合某个预期值;
• Pod期待的副本数;
• 用于筛选目标Pod的Label Selector;
• 当Pod副本数量小于预期数量的时候,用于创建新Pod的Pod模板(template);
Service
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,用户不需要了解后台Pod是如何运行。
一个service定义了访问pod的方式,就像单个固定的IP地址和与其相对应的DNS名之间的关系。
Service其实就是我们经常提起的微服务架构中的一个"微服务",通过分析、识别并建模系统中的所有服务为微服务——
Kubernetes Service,最终我们的系统由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过TCP/IP进行
通信,从而形成了我们强大而又灵活的弹性网络,拥有了强大的分布式能力、弹性扩展能力、容错能力;
如图示,每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,多个Pod副本组成了一个集群来提供服务,一般的做法是部署一个负载均衡器来访问它们,为这组Pod开启一个对外的服务端口如8000,并且将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端可以通过负载均衡器的对外IP地址+服务端口来访问此服务。运行在Node上的kube-proxy其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并且在内部实现服务的负载均衡与会话保持机制。Service不是共用一个负载均衡器的IP地址,而是每个Servcie分配一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。
Cluster IP
Service的IP地址,特性:
• 仅仅作用于Kubernetes Servcie这个对象,并由Kubernetes管理和分配IP地址;
• 无法被Ping,因为没有一个"实体网络对象"来响应;
• 只能结合Service Port组成一个具体的通信端口;
• Node IP网、Pod IP网域Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与IP路由有很大的不同
(Cluster IP也叫internal IP集群内部子u眼提供服务 区别与 external IP对外提供服务,但只能在gc2上使用因特殊原因暂时不能用)
Label
Kubernetes中的任意API对象都是通过Label进行标识,Label的实质是一系列的K/V键值对。Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
一个label是一个被附加到资源上的键/值对,譬如附加到一个Pod上,为它传递一个用户自定的并且可识别的属性.Label还可以被应用来组织和选择子网中的资源
selector是一个通过匹配labels来定义资源之间得表达式,例如为一个负载均衡的service指定所目标Pod
Label可以附加到各种资源对象上,一个资源对象可以定义任意数量的Label。给某个资源定义一个Label,相当于给他打一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象。我们可以通过给指定的资源对象捆绑一个或多个Label来实现多维度的资源分组管理功能,以便于灵活,方便的进行资源分配、调度、配置、部署等管理工作。
Node
Node是Kubernetes集群架构中运行Pod的服务节点(亦叫agent或minion)。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。
Endpoint (IP+Port)
标识服务进程的访问点:
注:Node、Pod、Replication Controller和Service等都可以看作是一种"资源对象",几乎所有的资源对象都可以通过Kubernetes通过的kubecti工具执行增、删、改、查等操作并将其保存在etcd中持久化存储。
Volume
数据卷,挂载宿主机文件、目录后者外部存储到Pod中,为应用服务提供存储,也可以Pod中容器之间共享数据。
StatefulSet
StatefulSet主要用来部署有状态应用,能够保证Pod的每个副本在整个生命周期中名称是不变的。而其他Controller不提供这个功能,当某个Pod发生故障需要删除并重新启动时,Pod的名称会发生变化。同时StatefulSet会保证副本按照固定的顺序启动、更新或者删除。
StatefulSet适合持久化性的应用程序,有唯一的网络标识符(IP),持久存储,有序的部署、扩展、删除和滚动更新。
Kubernetes架构与组件
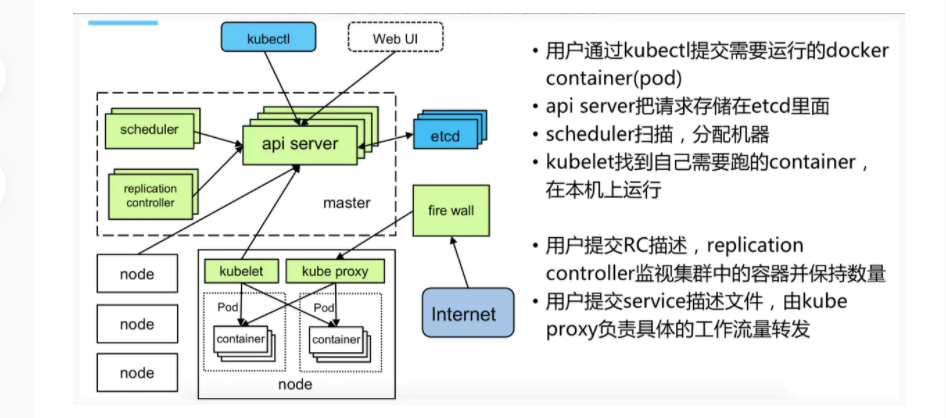
主从分布式架构,Master/Node
• 服务分组,小集群,多集群
• 服务分组,大集群,单集群
组件:
Kubernetes Master:
集群控制节点,负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都是发给它,他来负责具体的执行过程,我们后面所有执行的命令基本都是在Master节点上运行的;
包含如下组件:
1.Kubernetes API Server
作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用。维护的REST对象持久化到Etcd中存储。
2.Kubernetes Scheduler
为新建立的Pod进行节点(node)选择(即分配机器),负责集群的资源调度。组件抽离,可以方便替换成其他调度器。
3.Kubernetes Controller
负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。
• Replication Controller
管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。
⚪ Deployment Controller
管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当 Deployment更新时,控制实现Replication Controller和Pod的更新。
• Node Controller
管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。
• Namespace Controller
管理维护Namespace,定期清理无效的Namespace,包括Namespace下的API对象,比如Pod、Service等。
• Service Controller
挂你维护Service,提供负载以及服务代理。
• EndPoints Controller
管理维护EndPoints,关联Service和Pod,创建EndPoints为Service的后缀,当Pod发生变化时,实时更新EndPoints。
• Service Account Controller
管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。
• Persistent Volume Controller
管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。
• Daemon Set Controller
管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。
• Job Controller
管理维护Job,为Job创建一次性任务Pod,保证完成Job指定完成的任务数目。
• Pod Autoscaler Controller
实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
Kubernetes Node:
除了Master,Kubernetes集群中的其他集群被称为Node节点,Node节点才是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机,其上的工作负载会被Master自动转移到其他节点上去;
包含如下组件:
1.Kubelet
负责管理容器,Kubelet会从Kubernetes API Server接收Pod的创建请求、启动和停止容器,监控容器运行状态并汇报给Kubernetes API Service。
2.Kubernetes Proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service信息,并根据Service的信息创建代理服务,实现Service到Pod的请求路由和转发,从而实现Kubernetes层级的虚拟转发网络。
3.Docker Engine (docker),Docker引擎,负责本机的容器创建和管理工作;
数据库
etcd数据库,可以部署到master上,也可以独立部署
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息。
部署Kubernetes 集群-二进制方式(一)
部署方式:
方式1. minikube
Minikube时一个工具,可以在本地快速运行一个单点的Kubernetes,尝试Kubernetes或日常开发的用户使用。不能用于生产环境。
官方地址:https://kubernetes.io/docs/setup/minikube/
方式2. kubeadm
Kubeadm也是一个工具,提供Kubeadm init和Kubeadm join,用于快速部署Kubernetes集群。
官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeamd/
方式3. 直接使用epel-release yum源,缺点就是版本较低
方式4. 二进制包
从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
官方也提供了一个互动测试环境供大家测试:https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/cluster-interactive/
目标任务:
1 Kubernetes集群部署架构规划
2 部署Etcd集群
3 在Node节点安装Docker
4 部署Flannel网络
5 在Master节点部署组件
6 在Node节点部署组件
7 查看集群状态
8 运行一个测试示例
9 部署Dashboard (Web UI)
固定IP、改名字、相互解析、关闭防火墙、先做个快照
1、Kubernetes集群部署架构规划
操作系统:
CentOS7.6_x64
软件版本:
Docker 18.09.0-ce
Kubernetes 1.11
服务器角色、IP、组件:
k8s-master1
10.206.240.188 kube-apiserver,kube-apiserver,kube-controller-manager,kube-scheduler,etcd
k8s-master2
10.206.240.189 kube-apiserver,kube-apiserver,kube-controller-manager,kube-scheduler,etcd
k8s-node1
10.206.240.111 kubelet,kube-proxy,docker,flannel,extd
k8s-node2
10.206.240.112 kubelet,kube-proxy,docker,flanner
Master负载均衡
10.206.176.19 LVS
镜像仓库
10.106.240.188 Harbor
拓扑图
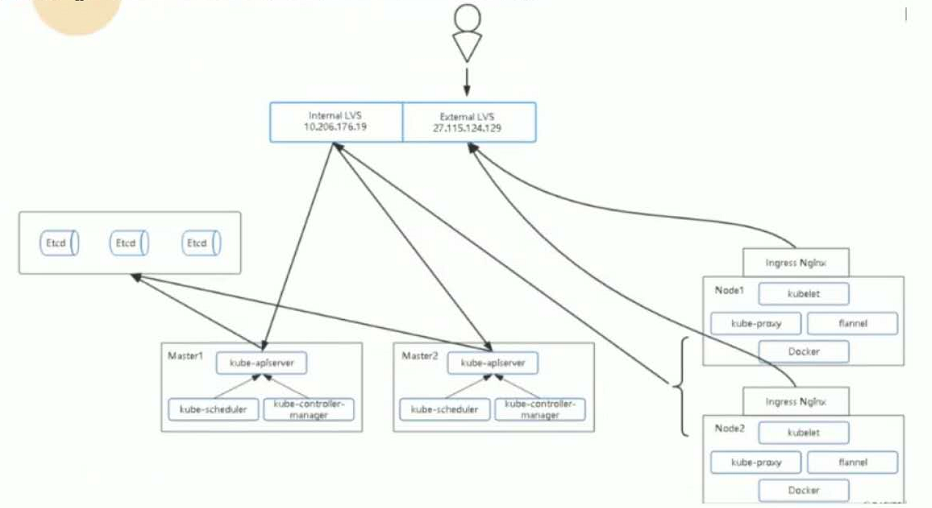
负载均衡器:
云环境:
可以采用slb
非云环境:
主流的软件负载均衡器,例如LVS、HAProxy、Nginx
这里采用Nginx作为apiserver负载均衡器,架构图如下:
2.安装nginx使用stream模块作4层反向代理配置如下:
user nginx;
worker_processes 4;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 10.206.240.188:6443;
server 10.206.240.189:6443;
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
3.部署Etcd集群
使用cfssl来生成自签证书,任何机器都行,证书这块儿知道怎么生成、怎么用即可,暂且不用过多研究。
下载cfssl工具:
# wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
# wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
# wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
# chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
# mv cfssl_linux-amd64 /usr/local/bin/cfssl
# mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
# mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo
生成Etcd证书:
创建以下三个文件:
# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"etcd": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
# cat ca-csr.json
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
# cat server-csr.json
{
"CN": "etcd",
"hosts": [
"10.0.4.121",
"10.0.4.122",
"10.0.4.123"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
生成证书:
# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
# cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=etcd \
server-csr.json | cfssljson -bare server
# ls *pem
ca-key.pem ca.pem server-key.pem server.pem
安装Etcd:
二进制包下载地址:
https://github.com/coreos/etcd/releases/tag/v3.2.12
https://github.com/etcd-io/etcd/releases/download/v3.2.12/etcd-v3.2.12-linux-amd64.tar.gz
以下部署步骤在规划的三个etcd节点操作一样,唯一不同的是etcd配置文件中的服务器IP要写当前的:
解压二进制包:
# mkdir /opt/etcd/{bin,cfg,ssl} -p
# tar -zxvf etcd-v3.2.12-linux-amd64.tar.gz
# mv etcd-v3.2.12-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
创建etcd配置文件:
# cat /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd01"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://10.206.240.188:2380"
ETCD_LISTEN_CLIENT_URLS="https://10.206.240.188:2379"
#
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.206.240.188:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://10.206.240.188:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://10.206.240.188:2380,etcd02=https://10.206.240.111:2380,etcd03=https://10.206.240.112:2380"
ETCD_INITIAL_CLUSTER_TOKEN="fucking-etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
* ETCD_NAME 节点名称 修改
* ETCD_DATA_DIR 数据目录
* ETCD_LISTEN_PEER-URLS 集群通信监听地址 修改
* ETCD_LISTEN_CLIENT_URLS 客户端访问监听地址 修改
* ETCD_INTIAL_ADVERTISE_PEER_URLS 集群通告地址 修改
* ETCD_ADVERTISE_CLIENT_URLS 客户端通告地址 修改
* ETCD_INTIAL_CLUSTER 集群节点地址 修改
* ETCD_INTIAL_CLUSTER_TOKEN 集群Token 修改
* ETCD_INTIAL_CLUSTER_STATE 加入集群的当前状态,nwe是新集群,existing表示加入已有集群
systemd管理etcd:
# cat /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
#
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd
ExecStart=/opt/etcd/bin/etcd \
--name=${ETCD_NAME} \
--data-dir=${ETCD_DATA_DIR} \
--listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \
--listen-client-urls=${ETCD_LISTEN_CLIENT_URLS},http://127.0.0.1:2379 \
--advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \
--initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \
--initial-cluster=${ETCD_INITIAL_CLUSTER} \
--initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \
--initial-cluster-state=${ETCD_INITIAL_CLUSTER_STATE} \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem
Restart=on-failure
LimitNOFILE=65536
#
[Install]
WantedBy=multi-user.target
把刚才生成的证书拷贝到配置文件中的位置:
# cp ca*pem server*pem /opt/etcd/ssl
启动并设置开启启动
# systemctl start etcd
# systemctl enable etcd
都部署完成后,检查etcd集群状态:
# /opt/etcd/bin/etcdctl \
--ca-file=/opt/etcd/ssl/ca.pem \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--endpoints="https://10.206.240.188:2379,https://10.206.240.111:2379,https://10.206.240.112:2379" \
cluster-health
member 18218cfabb349dea is healthy: got healthy result from https://10.206.240.111:2379
member 541c1c40995c949b is healthy: got healthy result from https://10.206.240.189:2379
member a342ea2875d20705 is healthy: got healthy result from https://10.260.204.188:2379
cluster is healthy
如果输出上面信息,就说明集群部署成功。
如果有问题第一步先看日志:/var/log/messages 或 journalctl -xeu etcd
报错:
Jan 15 12:06:55 k8s-master1 etcd: request clustrt ID mismatch (got 99f4702593c94f98 want cdf818194e3a8c32)
解决:因为集群搭建过程,单独启动过单一etcd,做为测试验证,集群内第一次启动其他etcd服务时候,是通过发现服务引导的,所以需要删除旧的成员信息,所有节点作以下操作
[root@k8s-master1 default.etcd]# pwd
/var/lib/etcd/default.etcd
[roto@k8s-master1 default.etcd]# rm -rf member/
在Node节点安装Docker
# yum -y install yum-utils device-mapper-persistent-data lvm2
# yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# yum install -y docker-ce
# curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://bc437cce.m.daocloud.io
# systemctl start docker
# systemctl enable docker
部署Flannel网络
工作原理:
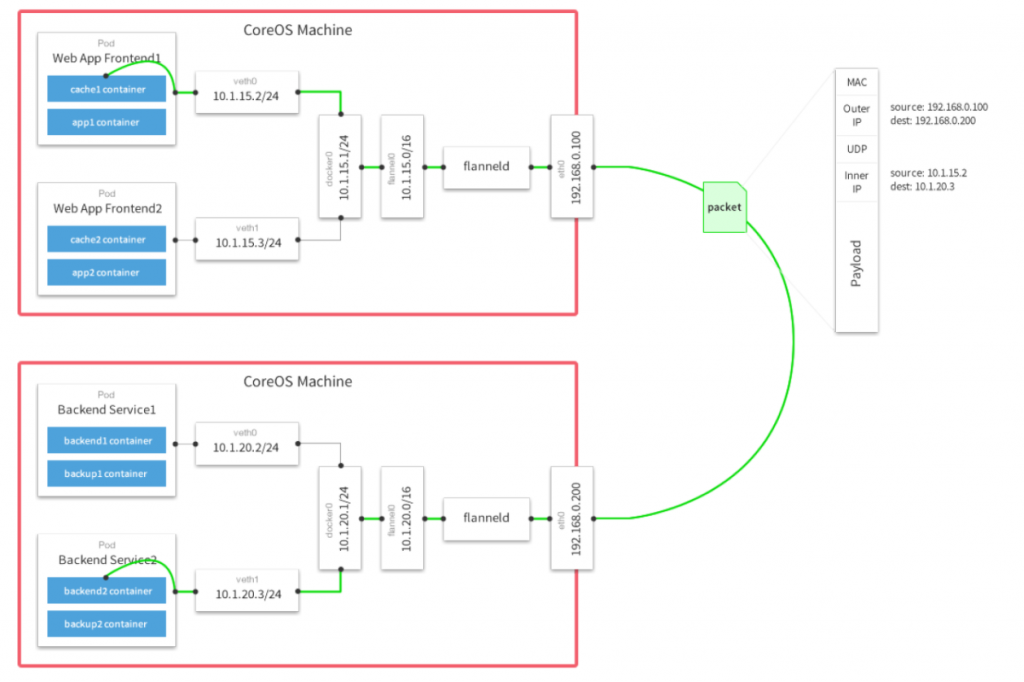
Falnnel要用etcd存储自身一个子网信息,所以要保证能成功连接Etcd,写入预定义子网段:
# 这里的预定义字段是 "172.17.0.0/16",推荐用这个,与 docker 原生网段一致
# /opt/etcd/bin/etcdctl \
--ca-file=ca.pem \
--cert-file=server.pem \
--key-file=server-key.pem \
--endpoints="https://10.206.240.188:2379,https://10.206.240.111:2379,https://10.206.240.112:2379" \
set /coreos.com/network/config '{"Network": "172.17.0.0/16", "Backend": {"Type": "vxlan"}}'
先要切换到etc认证目录,即/opt/etcd/ssl/
以下部署步骤在规划的每个node节点都操作。
下载二进制包:
# wget https://github.com/coreos/flannel/releases/download/v0.10.0/flannel-v0.10.0-linux-amd64.tar.gz
# tar -zxvf flannel-v0.10.0-linux-amd64.tar.gz
# mkdir -pv /opt/kubernetes/bin
# mv flanneld mk-docker-opts.sh /opt/kubernetes/bin
配置Flannel:
# mkdir -pv /opt/kubernetes/cfg/
# cat /opt/kubernetes/cfg/flanneld
FLANNEL_OPTIONS="--etcd-endpoints=https://10.206.240.188:2379,https://10.206.240.189:2379,https://10.206.240.111:2379 -etcd-cafile=/opt/etcd/ssl/ca.pem -etcd-certfile=/opt/etcd/ssl/server.pem -etcd-keyfile=/opt/etcd/ssl/server-key.pem"
systemd管理Flannel:
# cat /usr/lib/systemd/system/flanneld.service
[Unit]
Description=Flanneld overlay address etcd agent
After=network-online.target network.target
Before=docker.service
#
[Service]
Type=notify
EnvironmentFile=/opt/kubernetes/cfg/flanneld
ExecStart=/opt/kubernetes/bin/flanneld --ip-masq $FLANNEL_OPTIONS
ExecStartPost=/opt/kubernetes/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/subnet.env
Restart=on-failure
#
[Install]
WantedBy=multi-user.target
配置Docker启动指定子网段:
# cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/run/flannel/subnet.env
ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
从其他节点拷贝证书文件到node1和2上:因为node1和2没有证书,但是flannel需要证书
# mkdir -pv /opt/etcd/ssl/
# scp /opt/etcd/ssl/* k8s-node2:/opt/etcd/ssl/
重启flannel和docker:
# systemctl daemon-reload
# systemctl start flanneld
# systemctl enable flanneld
# systemctl restart docker
检查是否生效:
# ps -ef | grep docker
root 20941 1 1 Jun28 ? 09:15:34 /usr/bin/dockerd --bip=172.17.34.1/24 --ip-masq=false --mtu=1450
#ip a
3607: flannel.1 <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 8a:2e:3d:09:dd:82 brd ff:ff:ff:ff:ff:ff
inet 172.17.34.0/32 scope global flannel.1
valid_lft forever perferred_lft forever
3608:docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue start UP
link/ether 02:42:31:8f:d3:02 rbd ff:ff:ff:ff:ff:ff
lnet 172.17.34.1/24 brd 172.17.34.255 scope global docker0
valid_lft forever preferred-lft forever
inet6 fe80::42:31ff:fe8f:d302/64 scope link
valid_lft forever preferred_lft forever
确保docker0与flannel.1在同一网段
·测试不同节点互通,在当前节点访问另一个Node节点docker0 IP:
# ping 172.17.58.1
PING 172.17.58.1 (172.17.58.1) 56(84) bytes of data.
64 bytes from 172.17.58.1: icmp_seq=1 ttl=64 time=0.263 ms
64 bytes from 172.17.58.1: icmp_seq=1 ttl=64 time=0.204 ms
如果能通说明Flannel部署成功,如果不通检查下日志:journalctl -u flannel
部署kubernetes集群-二进制方式(二)
在Master节点部署组件
两个Master节点部署方式一样
在部署Kubernetes之前一定要确保etcd、flannel、docker是正常工作的,否则先解决问题再继续。
生成证书
创建CA证书
# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
# cat ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
生成apiserver证书:
# cat kube-apiserver-csr.json
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1", //这个是后面dns要用的虚拟网络的网关,不用改,就用这个,切记
"127.0.0.1",
"10.206.240.188",
"10.206.240.189",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-apiserver-csr.json | cfssljson -bare kube-apiserver
生成kube-proxy证书:
# cat kube-proxy-csr.json
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
最终生成以下证书文件:
# ls *pem
ca-key.pem ca.pem kube-apiserver-key.pem kube-apiserver.pem kube-proxy-key.pem kube-proxy.pem
部署apiserver组件
下载二进制包: https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.11.md
或者
https://dl.k8s.io/v1.11.0/kubernetes-server-linux-amd64.tar.gz
下载这个包(kubernetes-server-linux-amd64.tar.gz)就够了,包含了所需的所有组件。
# mkdir /opt/kubernetes/{bin,cfg,ssl} -pv
# tar -zxvf kubernetes-server-linux-amd64.tar.gz
# cd kubernetes/server/bin
# cp kube-apiserver kube-scheduler kube-controller-manager kubectl /opt/kubernetes/bin/
从生成证书的机器拷贝证书到master1,master2:
# scp *pem k8s-master1:/opt/kubernetes/ssl/
# scp *pem k8s-master2:/opt/kubernetes/ssl/
创建token文件,后面会讲到:
# cat /opt/kubernetes/cfg/token.csv
1111222233334444aaaabbbbccccdddd,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
第一列:随机字符串,自己可生成,第二列:用户名,第三列:UID,第四列:用户组
创建apiserver配置文件:
# cat /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://10.206.140.189:2379,https://10.206.240.188:2379,https://10.206.240.111:2379 \
--bind-address=10.206.240.189 \
--secure-port=6443 \
--advertise-address=10.206.240.189 \
--allow-privileged=true \
--service-cluster-ip-range=10.0.0.0/24 \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota,NodeRestriction \
--authorization-mode=RBAC,Node \
--enable-bootstrap-token-auth \
--token-auth-file=/opt/kubernetes/cfg/token.csv \
--service-node-port-range=30000-50000 \
--tls-cert-file=/opt/kubernetes/ssl/kube-apiserver.pem \
--tls-private-key-file=/opt/kubernetes/ssl/kube-apiserver-key.pem \
--client-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \
--etcd-cafile=/opt/etcd/ssl/ca.pem \
--etcd-certfile=/opt/etcd/ssl/server.pem \
--etcd-keyfile=/opt/etcd/ssl/server-key.pem"
配置好前面生成的证书,确保能连接etcd。
参数说明:
- –logtostderr 启用日志
- –v 日志等级
- –etcd-servers etcd集群地址
- –bind-address 监听地址
- –secure-port https安全端口
- –advertise-address 启用授权
- –service-cluster-ip-range Service虚拟IP地址段 //这里就用这个地址段,不用改
- –enable-admission-plugins 准入控制模块
- –authorization-mode 认证授权,启用RBAC授权和节点自管理
- –enable-bootstrap-token-auth 启用TLS bootstrap功能,后面会讲到
- –token-auth-file token文件
- –service-node-port-range Service Node类型默认分配端口范围
systemd管理apiserver:
# cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
#
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-apiserver
ExecStart=/opt/kubernetes/bin/kube-apiserver $KUBE_APISERVER_OPTS
Restart=on-failure
#
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl start kube-apiserver
# systemctl enable kube-apiserver
部署schdule组件
创建schduler配置文件:
# cat /opt/kubernetes/cfg/kube-scheduler
KUBE_SCHEDULER_OPTS="--logtostderr=true --v=4 --master=127.0.0.1:8080 --leader-elect"
- 参数说明:
- –master 连接本地apiserver
- –leader-elect 当该组件启动多个时,自动选举(HA)
systemd管理schduler组件:
# cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
#
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-scheduler
ExecStart=/opt/kubernetes/bin/kube-scheduler $KUBE_SCHEDULER_OPTS
Restart=on-failure
#
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl start kube-scheduler
# systemctl enable kube-scheduler
部署controller-manager组件
创建controller-manager配置文件:
# cat /opt/kubernetes/cfg/kube-controller-manager
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=true \
--v=4 \
--master=127.0.0.1:8080 \
--leader-elect=true \
--address=127.0.0.1 \
--service-cluster-ip-range=10.0.0.0/24 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \
--root-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem"
systemd管理controller-manager组件:
# cat /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
#
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-controller-manager
ExecStart=/opt/kubernetes/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
#
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl start kube-controller-manager
# systemctl enable kube-controller-manager
所有组件都已经启动成功,通过kubectl工具查看当前集群组件状态:
# /opt/kubernetes/bin/kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
controller-manager Healthy ok
如上输出说明组件都正常。
在Node节点部署组件
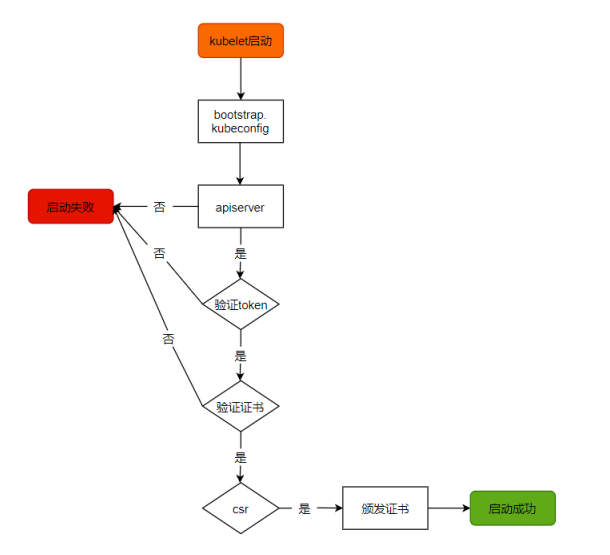
Master apiserver启用TLS认证后,Node节点kubelet组件想要加入集群,必须使用CA签发时有效证书才能与apiserver通信,当Node阶段很多时,签署证书是一件很繁琐的事情,因此有了TLS Bootstrapping机制,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。
-------------------------------------下面这些操作在master节点完成:-----------------------------------
将kubelet-bootstrap用户绑定到系统集群角色
# /opt/kubernetes/bin/kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
创建kubeconfig文件:
在生成kubernetes证书的目录下执行以下命令生成kubeconfig文件:
指定apiserver 内网负载均衡地址
# export BOOTSTRAP_TOKEN=1111222233334444aaaabbbbccccdddd
# export KUBE_APISERVER="https://10.206.176.19:6443"
# 设置集群参数
# /opt/kubernetes/bin/kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
# 设置客户端认证参数
# /opt/kubernetes/bin/kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
# 设置上下文参数
# /opt/kubernetes/bin/kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
# 设置默认上下文
# /opt/kubernetes/bin/kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
#----------------------------
# 创建kube-proxy kubeconfig文件
# /opt/kubernetes/bin/kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
# /opt/kubernetes/bin/kubectl config set-credentials kube-proxy \
--client-certificate=kube-proxy.pem \
--client-key=kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
# /opt/kubernetes/bin/kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
# /opt/kubernetes/bin/kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
# ls
bootstrap.kubeconfig kube-proxy.kubeconfig
!!! !!! 将这两个文件拷贝到Node节点/opt/kubernetes/cfg目录下。 !!!不能忽略
-------------------------------------------下面这些操作在所有node节点完成:-------------------------
部署kubelet组件
将前面下载的二进制包中的kubelet和kube-proxy拷贝到/opt/kubernetes/bin目录下。
创建kubelet配置文件:
# vim /opt/kubernetes/cfg/kubelet
KUBELET_OPTS="--logtostderr=true \
--v=4 \
--address=10.206.240.112 \
--hostname-override=10.206.240.112 \
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
--experimental-bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
--config=/opt/kubernetes/cfg/kubelet.config \
--cert-dir=/opt/kubernetes/ssl \
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"
参数说明
- –hostname-override 在集群中显示的主机名
- –kubeconfig 指定kubeconfig文件位置,会自动生成
- –bootstrap-kubeconfig 指定刚才生成的bootstrap.kubeconfig文件
- –cert-dir 颁发证书存放位置
- –pod-infra-container-image 管理Pod网络的镜像
其中/opt/kubernetes/cfg/kubelet.config配置文件如下:
# vim /opt/kubernetes/cfg/kubelet.config
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 10.206.240.112
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS: ["10.0.0.2"]
clusterDomain: cluster.local.
failSwapOn: false
authentication:
anonymous:
enabled: true
webhook:
enabled: false
systemd管理kubelet组件:
# vim /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
After=docker.service
Requires=docker.service
#
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet
ExecStart=/opt/kubernetes/bin/kubelet $KUBELET_OPTS
Restart=on-failure
KillMode=process
#
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl start kubelet
# systemctl enable kubelet
在Master审批Node加入集群:
启动后还加入到集群中,需要手动允许该节点才可以,在Master节点查看请求签名的Node:
# /opt/kubernetes/bin/kubectl get csr
# /opt/kubernetes/bin/kubectl certificate approve XXXXID
# /opt/kubernetes/bin/kubectl get node
在所有node节点操作kube-proxy
部署kube-proxy组件:
创建kube_proxy配置文件:
# cat /opt/kubernetes/cfg/kube-proxy
KUBE_PROXY_OPTS="--logtostderr=true \
--v=4 \
--hostname-override=10.206.240.111 \
--cluster-cidr=10.0.0.0/24 \
--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
systemd管理kube-proxy组件:
# cat /usr/lib/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-proxy
ExecStart=/opt/kubernetes/bin/kube-proxy $KUBE_PROXY_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl start kube-proxy
# systemctl enable kube-proxy
查看集群状态
# /opt/kubernetes/bin/kubectl get node
NAME STATUS ROLES AGE VERSION
10.206.240.111 Ready <none> 28d v1.11.0
10.206.240.112 Ready <none> 28d v1.11.0
# /opt/kubernetes/bin/kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
运行一个测试示例
创建一个Nginx Web,判断集群是否正常工作:
# /opt/kubernetes/bin/kubectl run nginx --image=nginx --replicas=3
# /opt/kubernetes/bin/kubectl expose deployment nginx --port=88 --target-port=80 --type=NodePort
查看Pod,Service:
# /opt/kubernetes/bin/kubectl get pods
NAME READY STATUS RESTART AGE
nginx-64f497f8fd-fjgt2 1/1 Running 3 28d
nginx-64f497f8fd-gmstq 1/1 Running 3 28d
nginx-64f497f8fd-q6wk9 1/1 Running 3 28d
查看pod详细信息:
# /opt/kubernetes/bin/kubectl describe pod nginx-64f497f8fd-fjgt2
# /opt/kubernetes/bin/kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 28d
nginx NodePort 10.0.0.175 <none> 88:38696/TCP 28d
打开浏览器输入地址:http://10.206.240.111:38696
恭喜你,集群部署成功!
部署Dashboard (web UI)
部署Dashboard(Web UI)
部署UI有三个文件:
- dashboard-deployment.yaml //部署Pod,提供Web服务
- dashboard-rbac.yaml //授权访问apiserver获取信息
- dashboard-service.yaml //发布服务,提供对外访问
# cat dashboard-deployment.yaml
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: kubernetes-dashboard
containers:
- name: kubernetes-dashboard
image: registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.7.1
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9090
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
# cat dashboard-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
name: kubernetes-dashboard
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
# cat dashboard-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 80
targetPort: 9090
创建:
# /opt/kubernetes/bin/kubectl create -f dashboard-rbac.yaml
# /opt/kubernetes/bin/kubectl create -f dashboard-deployment.yaml
# /opt/kubernetes/bin/kubectl create -f dashboard-service.yaml
等待数分钟:查看资源状态
# /opt/kubernetes/bin/kubectl get all -n kube-system
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-68ff5fcd99-5rtv7 1/1 Runnginx 1 27d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-doshboard NodePort 10.0.0.100 <none> 443:30000/TCP 27d
NAME
...
查看访问端口:
# /opt/kubernetes/bin/kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-doshboard NodePort 10.0.0.100 <none> 443:30000/TCP 27d
打开浏览器,输入:https://10.206.240.111:30000
查看token:
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret |awk '/dashboard-amdin/{pring $1}')
kuberadm方式部署Kubernetes
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
这个工具能通过两条指令完成一个kubernetes集群的部署:
# 创建一个 Master 节点
$ kubeadm init
# 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master节点的IP和端口>
1.安装要求
在开始之前,部署kubernetes集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
- 集群中所有集群之间网络互通
- 可以访问外网,需要拉取镜像
- 禁止swap分区
2.学习目标
1.在所有节点上安装Docker和kubeadm
2.部署kubernetes Master
3.部署容器网络插件
4.部署kubernetes Node,将节点加入kubernetes集群中
5.部署Dashboard Web页面,可视化查看kubernetes资源
3.环境准备
步骤
关闭防火墙:
# systemctl stop firewalld
# systemctl disable firewalld
关闭selinux:
# sed -i 's/enforcing/disabled' /etc/selinux/config
# setenforce 0
关闭swap:
# swapoff -a //临时
# vim /etc/fstab //永久
添加主机名与IP对应关系(记得设置主机名):
# cat /etc/hosts
192.168.31.63 k8s-master
192.168.31.65 k8s-node1
192.168.31.66 k8s-node2
hostnamectl set-hostname hostname
将桥接的IPv4流量传递到iptables的链:
# cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# sysctl --system
4.所有节点安装Docker/kubernetes/kubelet
kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker。
4.1 安装Docker
# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# yum install -y yum-utils device-mapper-persistent-data lvm2
# yum -y install docker-ce-18.06.1.ce-3.el7
# systemctl enable docker && systemctl start docker
# docker --version
Docker version 18.06.1-ce, build e68fc7a
配置docker镜像下载加速器
# cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://kwk8mr4s.mirror.aliyuncs.com"]
}
4.2 添加阿里云YUM软件源
# cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
4.3 安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
# yum -y install kubelet-1.14.0
# yum -y install kubectl-1.14.0
# yum -y install kubeadm-1.14.0
# systemctl enable kubelet
5.部署kubernetes Master
在192.168.31.63(Master)执行。
# kubeadm init \
--apiserver-advertise-address=192.168.31.63 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.14.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
由于默认拉取镜像地址ks.gcr.io国内无法访问,这里指定阿里云镜像仓库地址。
使用kubectl工具:
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
# kubectl get nodes
6.安装Pod网络插件(CNI)
# kubectl apply -f
https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml
或使用下列方式
git clone --depth 1 https://github.com/coreos/flannel.git
修改配置文件,将128行替换为PodIP,在189行新增加一行指定网卡名
cd flannel/Documentation/
vim kube-flannel.yml
128: "Network": "10.244.0.0/16",
189: - --iface=eth0
如果打不看使用curl访问,复制+粘贴
CNI.txt
确保能够访问到quay.io这个regittery。master执行
# kubectl get pods -n kube-system
7.加入kubernetes Node
在192.168.31.65/66(Node)执行。
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
# kubeadm join 192.168.31.63:6443 --token 179g5t.60v4jkddwqki1dxe discovery-token-ca-cert-hash sha256:4f07f9068c543130461c9db368d62b4aabc22105451057f887defa35f47fa076
测试kubernetes集群
在Kubernetes集群中创建一个pod,验证是否正常运行:
# kubectl create deployment nginx --image=nginx
# kubectl expose deployment nginx --port=80 --type=NodePort
# kubectl get pod,svc
# kubectl get pod,svc -o wide
访问地址:http:/NodeIP:Port
9.部署DashBoard
# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
curl -s https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
[http://www.zyixinn.com/wp-content/uploads/2021/04/dashboard.txt][http://www.zyixinn.com/wp-content/uploads/2021/04/dashboard.txt]
[http://www.zyixinn.com/wp-content/uploads/2021/04/dashboard.txt]: http://www.zyixinn.com/wp-content/uploads/2021/04/dashboard.txt
镜像下载因为网络的原因:
镜像难以下载,需要修改以下两个地方
image: tigerfive/kubernetes-dashboard-amd64:v1.10.1
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
selector:
k8s-app: kubernetes-dashboard
# kubectl apply -f kubernetes-dashboard.yaml
访问地址:https://nodePort
评论区